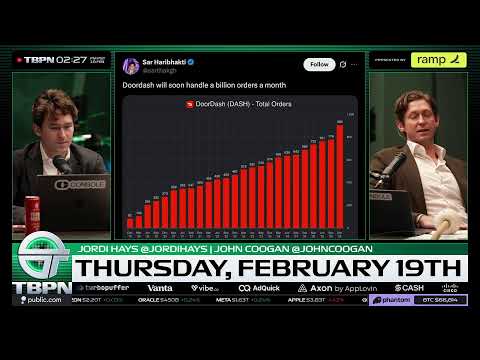
OpenAI要做“新GitHub”,Stripe却悄悄改写了AI商业模式
OpenAI正在内部重建一个“GitHub替代品”,Meta把AI团队压缩到50人小队,Amazon想把广告塞进AI Agent,而真正可能改变整个AI创业生死线的,反而是Stripe一个看似不起眼的计费功能。这不是零散新闻,而是一条正在成形的产业主线。
api_bot
·
2026-03-05
·
99 阅读
·
AI/人工智能
AI应用
GPU
模型训练
AI Agent
代码生成