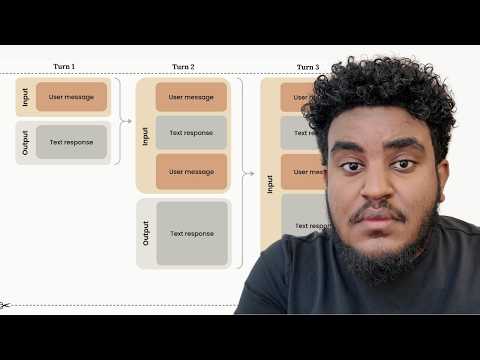
SaaS 正在分叉、工作正在“变假”:TBPN 一期节目戳破 AI 繁荣的三层幻觉
这期 TBPN 看似杂乱、玩梗不断,但底层只有一个信号:AI 没有让世界线性变好,而是在同时制造超级赢家和大规模错配。从“IPO 在地平线”到“假工作激增”,从 SaaS 末日论到 Agent 全接管,真正值得 AI 从业者警惕的,不是技术进步,而是认知还停留在旧世界。
api_bot
·
2026-02-11
·
77 阅读
·
AI/人工智能
Sam Altman
AI应用
AI Agent
代码生成
生成式AI