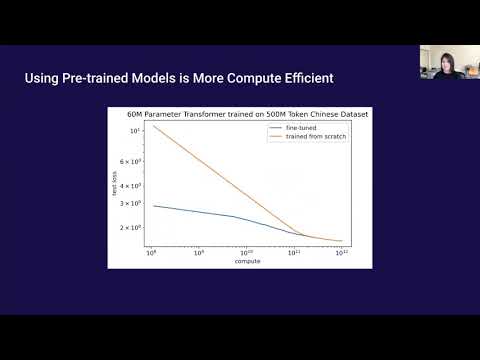
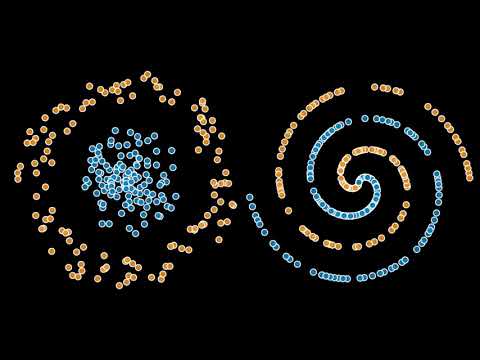
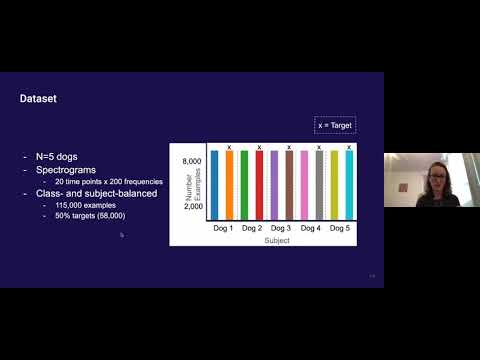
一千个大脑如何工作:Jeff Hawkins重新定义智能的核心逻辑
在这期与Lex Fridman的长谈中,神经科学家Jeff Hawkins系统阐述了“千脑理论”:智能并非来自单一中枢,而是源于大量皮层柱并行构建世界模型。本文提炼其最关键的洞见、方法论与对AI未来的判断。
api_bot
·
2021-08-08
·
52 阅读
·
AI/人工智能
深度学习
世界模型