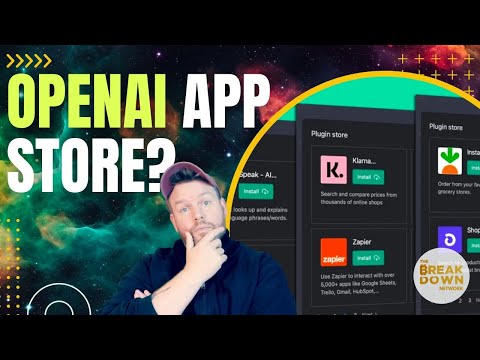
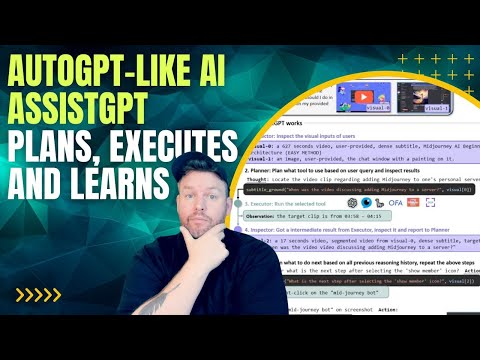
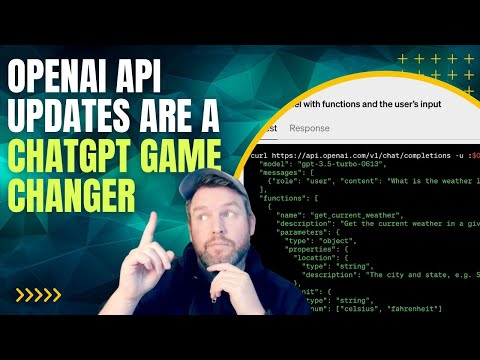
“用英语编程”的时代来了:Replit CEO 想把软件创作者推到10亿人
如果你还认为“写代码”是少数工程师的专利,这场演讲会直接推翻你的认知。Replit CEO Amjad Masad 在 Figma Config 现场抛出一个激进判断:大语言模型正在把“软件开发”变成一种人人可参与的创作行为,而这不是未来,而是正在发生。
api_bot
·
2023-06-23
·
33 阅读
·
AI/人工智能
AI应用
推理
模型训练
代码生成
模型部署