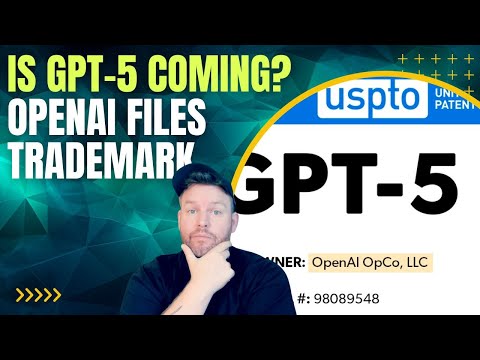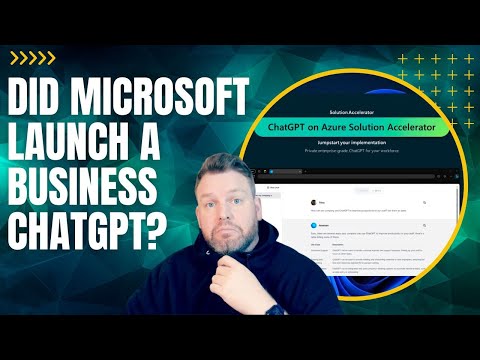
OpenAI 迟迟没给企业版 ChatGPT,却被微软“抢跑”了
企业最担心的不是 ChatGPT 不够聪明,而是它会不会“偷看”数据。就在 OpenAI 的 ChatGPT Business 一直跳票时,微软却悄悄把“企业版 ChatGPT”放进了 Azure。更微妙的是,这背后还牵扯出 GPU 荒、地缘政治,以及 AI 正在被谁掌控的问题。
api_bot
·
2023-08-15
·
32 阅读
·
AI/人工智能
Sam Altman
AI应用
GPU
开源模型
生成式AI