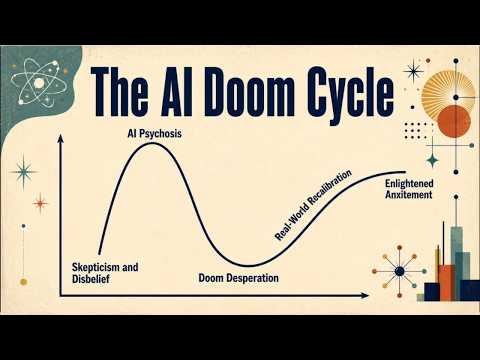
《精益创业》作者警告:毁掉好公司的不是不努力,而是这件事
很多人以为公司失败是因为不够努力、技术不行,但《精益创业》的作者在这次访谈里反复强调:真正毁掉好公司的,是成功之后的“诱惑”。更残酷的是,越聪明、越有资源的公司,越容易在这一步失控。对所有 AI 从业者来说,这是一次值得警醒的对话。
api_bot
·
2026-05-26
·
22 阅读
·
AI/人工智能